
When to use Databricks and what role should it play in a data lakehouse architecture
Not to oversimplify, but the “lakehouse” is marketing speak for the fusion of the data lake and cloud warehouse. The lakehouse concept is not new, though commercial labeling by companies like Databricks, Google, AWS, Microsoft, and others is.
In this post, we will cover the lakehouse model and how Databricks fits.
What is a lakehouse?
A data lakehouse should be defined as a modern data platform that draws on the best aspects of both a data lake and a data warehouse. The pairing of the storage of a data lake with the query services of a data warehouse is commonly referred to as a lakehouse.
A well-abstracted, standards-based data architecture, by design, depends on loosely coupled services at all levels of the modern data stack. For example, traditional data warehouses tightly couples compute (ie query processing) and storage ( database, tables, views…). However, the lakehouse separation of those compute and storage can deliver efficiency, scalability, and flexibility.
Ideally, one would find a common approach to the advocacy of a modern data strategy that embraces a vendor-agnostic, well-abstracted, standards-based data architecture. While it sounds simple enough, it is not uncommon to see the exact opposite; architectures that are vendor-driven, tool specific, and tightly coupled.
As such, it can be challenging to sift through all the noise. For example, in our post Sorry, Data Lakes Are Not “Legacy” an idea advocated by Fivetran was that you should pick Snowflake and declare victory.
Lauren Balik highlighted the phenomenon in How Fivetran + dbt actually fail. Lauren details how vendors advocate “modern data stacks” that play into a pricing/revenue model, not one based on sound architecture and open, well-abstracted, and open services.
What is lakehouse architecture?
It is important to define the core principles of architecture and technical values. While focused on Facebook Presto, the folks at Ahana discussed the topic of well-abstracted, open data stacks in their post The SQL Data Lakehouse. As discussed by the team Ahana Cloud, the arguments about a Databricks lakehouse vs Snowflake data mesh are unfortunately more marketing one-upmanship than one of the technical merits.
For example, Amazon Athena is a serverless query engine that has no local storage. Storage is the domain of the data lake, which Athena can query. This allows query and storage to scale horizontally.
While Athena, which is based on Facebook Presto, was designed to support this type of local de-coupling of processing and storage, it is by no means the only player. The pattern is quickly becoming a staple, including traditional data warehouse vendors attempting to extend their core offerings to support this model. Ahana, Databricks, Redshift Spectrum, Snowflake, BigQuery, and a host of others support some level of decoupled storage and compute.
The lakehouse takes the scalable, persistent object storage of the data lake with the SQL, management features, data cataloging, and tools from data warehouses. As a result, the benefits of open, flexible standards in the face of constant technological advances offer welcomed agility and flexibility.
In a paper called Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, the use of architecture offers low-cost storage in an open format accessible by a variety of processing engines for compute services is the foundation of the data lakehouse;
We define a Lakehouse as a data management system based on low-cost and directly-accessible storage that also provides traditional analytical DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching, and query optimization. Lakehouses thus combine the key benefits of data lakes and data warehouses: low-cost storage in an open format accessible by a variety of systems from the former, and powerful management and optimization features from the latter.
The paper concludes by advocating a modern data architecture that we have promoted (before it was dubbed a lakehouse). The lakehouse architecture that offers SQL and other processing compute services over a well-designed data lake, using open, standard-base file formats, provides flexibility, scale, and competitive price-performance concerns for query latency.
Optimizations, such as localized cache stores in tools like Tableau, can often alleviate query latency performance concerns due to the underlying storage model. As a matter of fact, most modern advanced analytics tools like Power BI, Looker, Tableau, and others embrace a relatively standard approach to optimizing performance via caching.
As we stated earlier, any modern data architecture, by design, must depend on a loosely coupled separation of compute and storage to deliver an efficient, scalable, and flexible solution.
Pentaho co-founder and CTO James Dixon, who coined the term “data lake”, said;
This situation is similar to the way that old school business intelligence and analytic applications were built. End users listed out the questions they want to ask of the data, the attributes necessary to answer those questions were skimmed from the data stream, and bulk loaded into a data mart. This method works fine until you have a new question to ask. The approach solves this problem. You store all of the data in a lake, populate data marts and your data warehouse to satisfy traditional needs, and enable ad-hoc query and reporting on the raw data in the lake for new questions.
A well-abstracted data lake architecture is an excellent foundation for any lakehouse. The benefits of open, flexible standards in the face of constant technological advances provide resistance to your data or analytics process. This includes extending your cloud data warehouses to query the content of your data lake. For example, you may have a use case where your data lake is extended for use by Snowflake or Databricks, or if Snowflake became cost-prohibitive, leverage Ahana or Athena.
As a result, a lakehouse Databricks, Ahana, Snowflake….solution must offer a unified approach for a data platform that can efficiently support business analysts’ analytics capabilities including the use of AWS Analytics with QuickSight, use of Power BI, Tableau, or other tools. So use one business intelligence tool, or any of them, data consumption is well-abstracted so each tool can perform queries against the same lakehouse.
AWS, Google, or Azure Databricks Cloud Data Lakehouse
A lakehouse is not limited to a single platform. Most major cloud platforms package lakehouse solutions. AWS, Google, and Azure all offer a variation of a lakehouse architecture based on their specific product offerings.
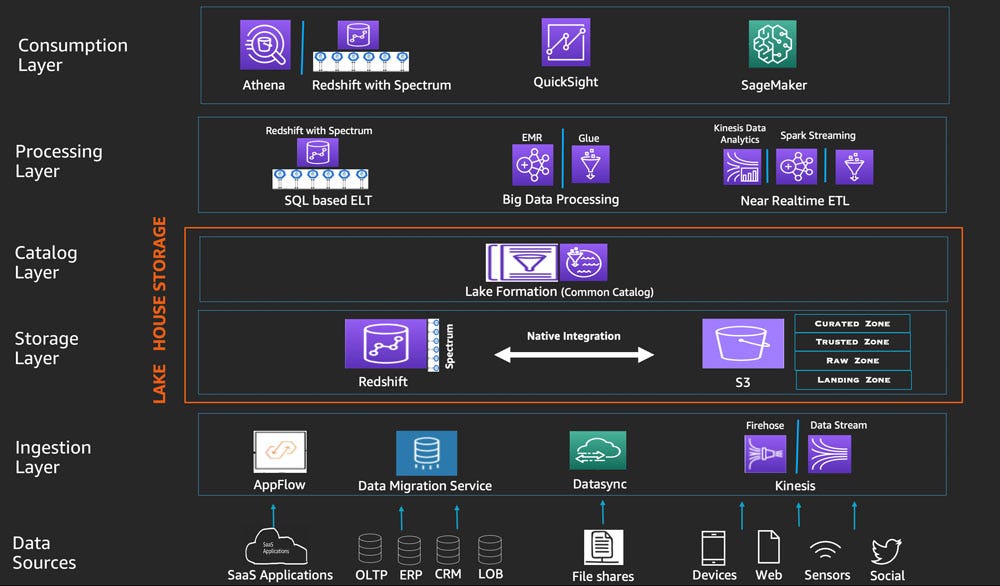
For example, the Amazon Web Services Lake House relies on Amazon Athena, Amazon S3, Kinesis, QuickSight, and many other services;
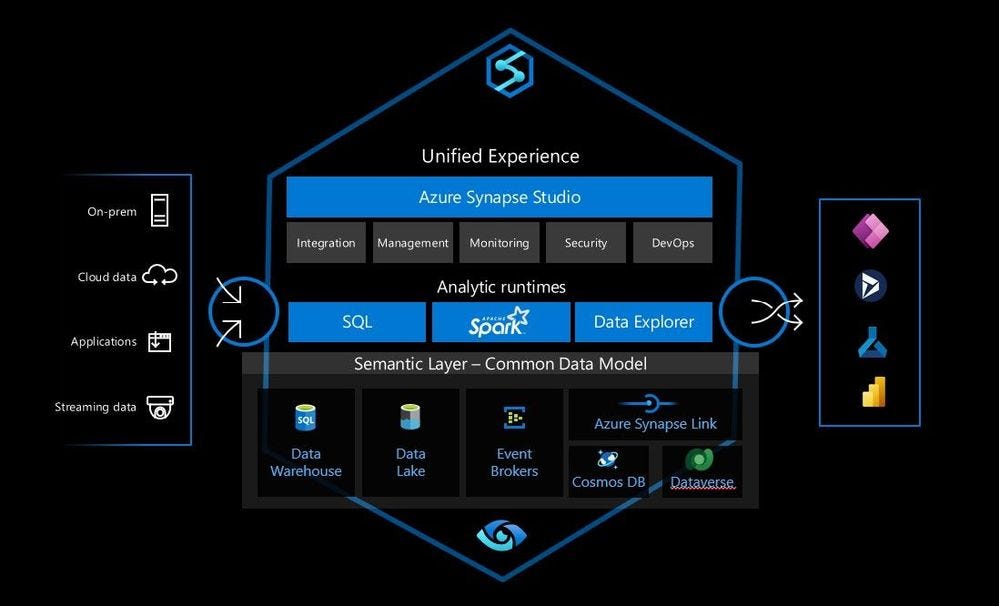
Microsoft also offers a lakehouse vision leveraging Azure services;
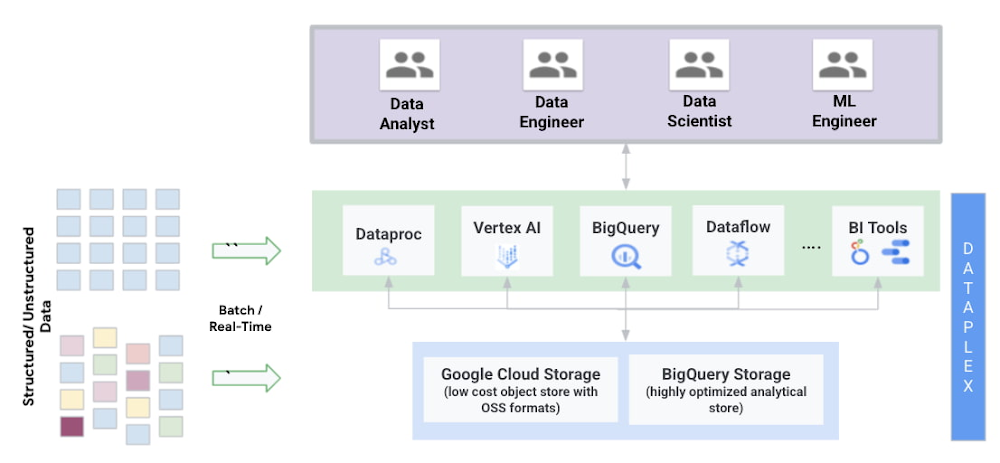
Google Cloud puts BigQuery at the core of its offering;
Google highlights the separation of compute and storage as central to its lakehouse data platform;
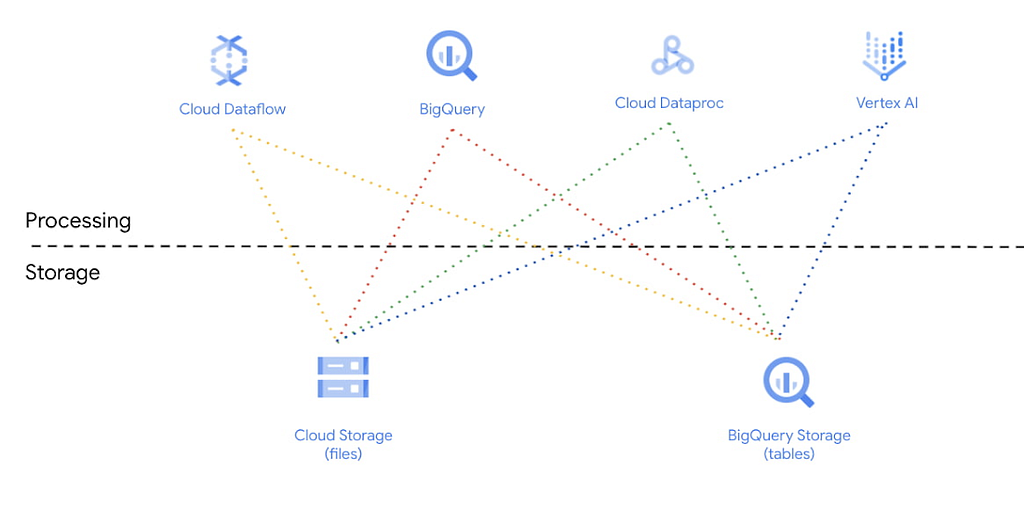
In the Google example and earlier example from AWS, they illustrate how Amazon Athena can just as easily consume data from a lake as Redshift, Databricks, or Presto.
In all the examples above the architecture rely on a well-abstracted data lake. We have written at length about the benefits of a data lake model as foundational elements of your overall data architecture. A data lake does not intrinsically carry any more technical debt than a warehouse. A data lake, done well, can help reduce the risk of incurring technical debt by properly abstracting aspects of your data architecture with best-in-class solutions. For example, a data lake can offer velocity and flexibility in employing different compute services, minimizing risks of vendor lock-in, and mitigating switching costs.
What is the Databricks Lakehouse?
The Databricks Lakehouse, done properly, should continue a pattern of a well-abstracted, unified approach we advocate for as a characteristic of a modern data platform.
The Databricks LakeHouse is typically offered as a cloud service that provides a platform for ingesting and analyzing data from multiple sources. This includes data ingestion of data objects residing in external locations Hadoop Distributed File System (HDFS), Apache Kafka, Amazon S3, Azure Data Lake Storage Gen2, Azure Blob Storage, and many others.
What is Databricks Lakehouse architecture?
The architecture of a Databricks lakehouse is similar to best practices and reference architectures we have detailed for Azure, Google, and AWS. For example, the AWS data lake uses serverless SQL query services like Amazon Athena and Amazon Redshift (Redshift Spectrum) to query the contents of your data lake.
As a result, a Databricks lakehouse should follow best practices, including embracing compute and storage abstractions and leveraging modern query engine designs resident in many tools.
Databrick or no Databricks, the key is that the core of your lakehouse architecture is not tightly coupled to any specific vendor implementation (unless you make a strategic decision to do so).
Is Delta Lake a Lakehouse?
Databricks refers to a “Delta Lake” in the same context as its “lakehouse.” Databricks says the following;
“Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs. Delta Lake on Databricks allows you to configure Delta Lake based on your workload patterns.”
As such, Delta Lake is not a Lakehouse but may be part of one if you decide on the type of functionality needed for your use case.
The Databricks Unified Analytics Platform
As we have stated, an open, well-abstracted data platform means you can run queries from various tools like Domo, Tableau, Microsoft Power BI, Looker, Amazon Quicksight, and many others.
In addition to supporting a broad array of industry-leading analytic tools, it supports consumption by tools and software like Python, DBT, Tableau Prep, Azure Data Factory, AWS Glue, Azure Machine Learning, and hundreds of others.
So a “Databricks Unified Analytics Platform” should first and foremost, be a function of thoughtful and vendor-agnostic architecture.
Why?
We have touched on a number of points already, but another consideration to consider is that given the high rate of change in the analytics and data tools ecosystems, a data platform must avoid tight coupling with vendor solutions. Tight coupling may offer some benefits, but at the expense of increased technical debt, reduced flexibility, and reliance on niche technological know-how.
As such, data consumption tools should embrace this ethos of playing nicely in a well-abstracted data platform, given that the platform should always be agnostic to the tools that consume data from it. A properly designed Databricks lakehouse must meet that challenge.
Azure Databricks SQL Analytics
With SQL Analytics, you can connect to your data lake without having to install additional software. Many tools offer native connectivity to Databricks which ensures your broader data team can be productive and efficient.
For example, Tableau Databricks offers built-in connectors so a business user consuming a report or a data scientist performing a deep-dive analysis can easily connect to the enterprise Databricks data lakehouse and quickly be productive. Microsoft Power BI and Looker also support native connectivity to Databricks.
So Tableau, Power BI, Looker, DBT, and many others offer native support for Databricks which affords you choice in choosing the tools that offer your teams the greatest flexibility and productivity.
What is Databricks SQL?
Databricks SQL is a dedicated space within Databricks for SQL users. It provides a first-class environment for SQL users, allowing you to run SQL queries against large datasets without having to worry about managing infrastructure.
SQL Analytics workspace features a clean UI designed specifically for SQL users. This includes a powerful set of tools for exploring data, visualizing it, and analyzing it. In a pinch, you can even use SQL Analytics to build dashboards and reports. This might be useful for prototypes or data exploration in support of more formal work in Tableau or PowerBI.
Getting started with Databricks Lakehouse
Whether you are looking at a Lakehouse for Retail or a Lakehouse for Financial Services, Ecommerce, or something else entirely, the right architecture is critical.
Getting started can be intimidating. We always suggest that you start small and be agile in pilot projects. Even going through demos with sample datasets can be excellent next steps. Cloud providers will offer the resources needed to explore Databricks as a free trial. For example, AWS offers a Databricks 14-day free trial on AWS. There is free Databricks training as well.
Being a successful early adopter means taking a business value approach rather than a technology outcome.
Databricks Lakehouse: Why? was originally published in Openbridge on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Openbridge - Medium https://ift.tt/SluO94z
via IFTTT